I heard about Dask at my local Python Meetup last month. After reading about it, I came across Matthew Rocklin’s Pycon 2017 talk on Dask and was blown away by his demo of crunching through around 20 gigs of csv data (60 gigs in memory) in matter of a minute. You have to see the demo to really appreciate the power of Dask. He also wrote an article on his blog, which goes over the same example.
I thought the best way to get started with Dask would be to re-create the demo. Reading on the blog, I saw that Matthew was using an eight node cluster on EC2 of m4.2xlarges (eight cores, 30GB RAM each). So I started to look into how to setup that eight node cluster. The main documentation now recommends deploying Dask with Kubernetes and Helm.
This is where my in-experience working with kubernetes became an obstacle. Luckily the documentation and watching a few youtube videos helped me get started. I am also doing all this from Windows 10 on WSL.
Steps to get this demo working!
1. Make sure your aws cli is setup. Read up install instructions here and configuring instructions here. In my case aws cli was already setup as I use it for other work.
2. Install Docker. As of May of 2019, docker does not work natively on WSL. The way around it is to have Docker be installed on windows and just install the docker client on WSL. Nick Janetakis has a great write up on his blog and I got docker working from WSL in no time.
3. Install kubectl. The official docs covers a lot of ways but none that covers wsl. I found a writeup on DevKimchi where I found out that the windows Docker settings has an option to enable Kubernetes. Once enabled just copy the configuration from windows into WSL and also install the kubernetes cli in WSL.
$ mkdir ~/.kube
$ cp /c/Users/[USERNAME]/.kube/config ~/.kube/
$ curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
$ chmod +x ./kubectl
$ sudo mv ./kubectl /usr/local/bin/kubectl
4. Install Kops. Kops is a tool used to create, destroy, upgrade and maintain production-grade, highly available, Kubernetes clusters from the command line. Installing on WSL was pretty straight forward.
$ curl -LO https://github.com/kubernetes/kops/releases/download/$(curl -s https://api.github.com/repos/kubernetes/kops/releases/latest | grep tag_name | cut -d '"' -f 4)/kops-linux-amd64
$ chmod +x kops-linux-amd64
$ sudo mv kops-linux-amd64 /usr/local/bin/kops
5. Setup AWS IAM group and user. I am going to create a group called kops and user called kops.
$ aws iam create-group --group-name kops
$ aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/AmazonEC2FullAccess --group-name kops
$ aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/AmazonRoute53FullAccess --group-name kops
$ aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/AmazonS3FullAccess --group-name kops
$ aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/IAMFullAccess --group-name kops
$ aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/AmazonVPCFullAccess --group-name kops
$ aws iam create-user --user-name kops
$ aws iam add-user-to-group --user-name kops --group-name kops
6. Set up an S3 bucket to save your cluster state. Just choose your own unique name.
$ aws s3api create-bucket --bucket some-kops-state-bucket --region us-east-1
7. Setup environment variables to help create our clusters. These variable names are defaults which are used by kops. Just make sure sure the cluster name you choose ends with “k8s.local”. You can also add this to your .bashrc file.
export KOPS_CLUSTER_NAME=somekops.k8s.local
export KOPS_STATE_STORE=s3://some-kops-state-bucket
8. Create your cluster. I am using 1 t3.xlarge (4cpu/16GB RAM) as my master and 8 m4.2xlarge (8 cpu/32GB RAM) as my worker nodes.
$ kops create cluster --name=${KOPS_CLUSTER_NAME} --node-count=8 --node-size=m4.2xlarge --master-size=c4.4xlarge --zones=us-east-2c
$ kops update cluster --name=${KOPS_CLUSTER_NAME} --yes
Validate your cluster with the command below -
$ kops validate cluster
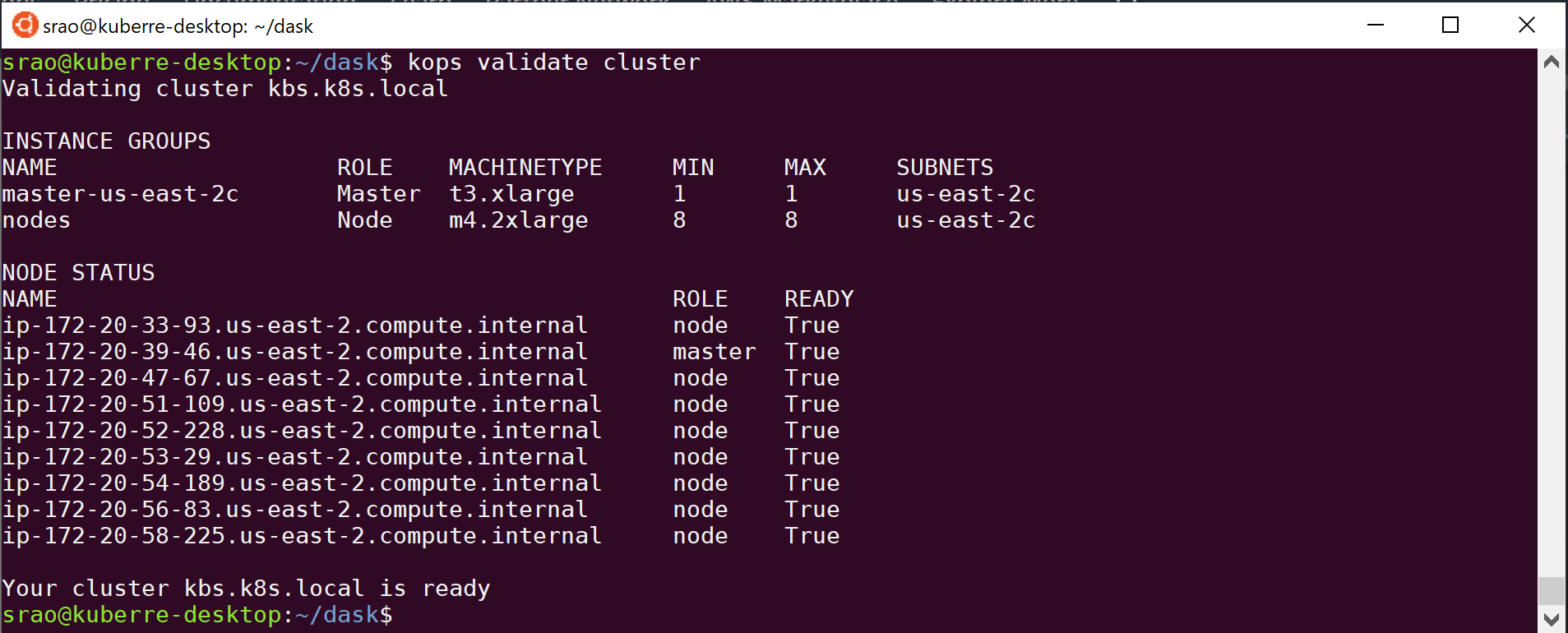
You should proceed further only after you see that your cluster is ready. This was also one of the pain points for me as I wasn’t sure why my clusters were not getting created properly. It turned out that it was due to AWS availability in the “us-east-1c” zone. I switched to “us-east-2c” and all was good.
9. Install Helm. Helm is your package manager for Kubernetes. We will install Dask on the kubernetes cluster we created using helm. Installing helm is pretty straight forward. Zero-to-jupyterhub docs do a great job.
$ curl https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get | bash
Now setup tiller on your kubernetes cluster
$ kubectl --namespace kube-system create sa tiller
$ kubectl create clusterrolebinding tiller --clusterrole cluster-admin --serviceaccount=kube-system:tiller
$ helm init --service-account tiller
Check if helm is installed correctly
$ helm version
Client: &version.Version{SemVer:"v2.13.1", GitCommit:"618447cbf203d147601b4b9bd7f8c37a5d39fbb4", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.13.1", GitCommit:"618447cbf203d147601b4b9bd7f8c37a5d39fbb4", GitTreeState:"clean"}
10. Install Dask on your cluster. The official docs have a good explanation on how to install a basic cluster. Here is the command
$ helm install stable/dask
The install gives a name to your deployment and you need to use this name if you want to upgrade or later delete your helm install. To validate if your install was successful and your pods are running, use the following command
$ kubectl get pods
Here is a screenshot of the stages the pods go through
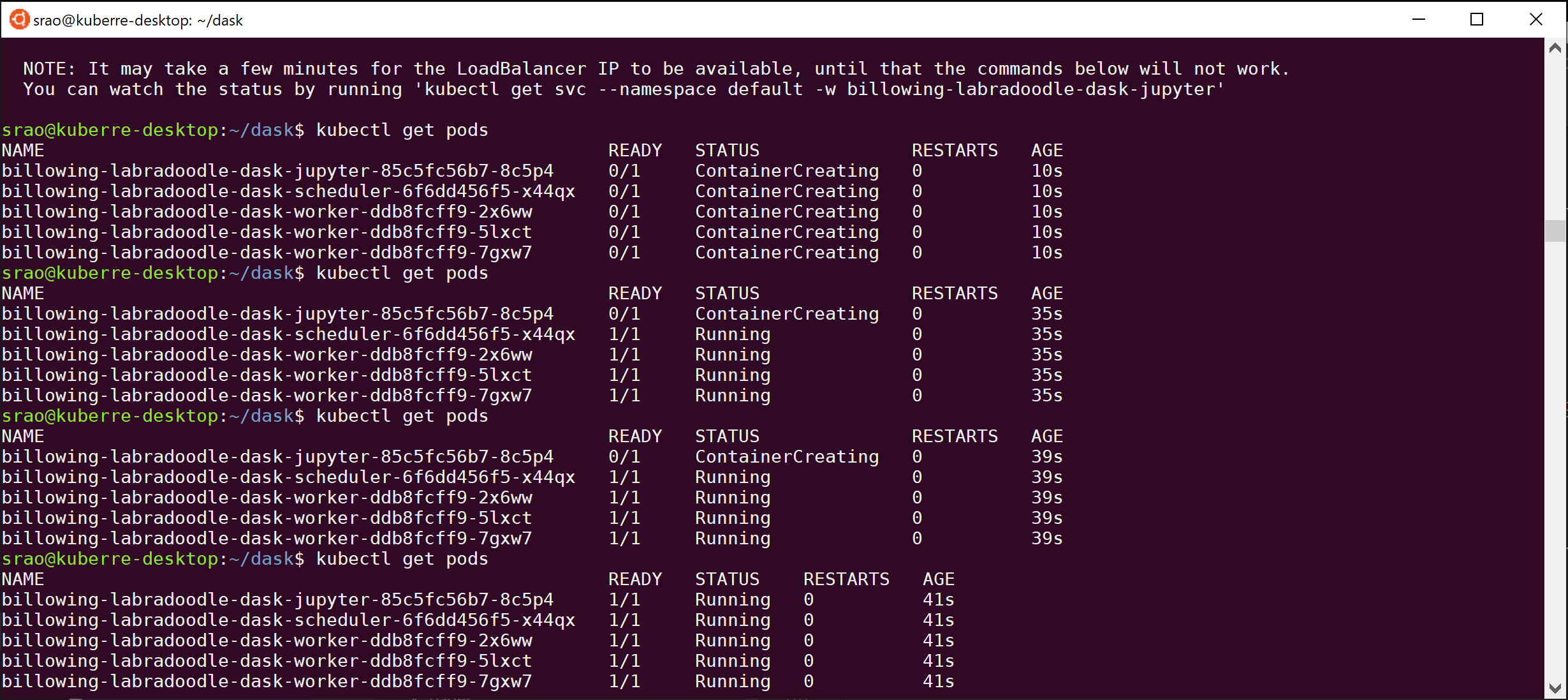
You can see here that the deployment gave my cluster the name of billowing-labradoodle and the status is running.
The thing which tripped me the most was the docs saying “By default, the Helm deployment launches three workers using two cores each and a standard conda environment.” So it took me a while to get to a Dask cluster which had 8 workers with 64 cores. The basic install does create a cluster with 1 jupyter server, 1 scheduler and 3 worker nodes, but the size of the worker nodes is based on your original node size you provisioned in step 8. After a few permutations, I realized I just want to say I want 8 replicas of the workers with my default kubernetes config for cpu and memory the way I set it up (8 cpu/32gig ram) for each worker. Another issue I faced was that the install has basic anaconda installed and thats it. So if you want to use s3 or Google cloud storage you need to have either s3fs or gcsfs installed on all your nodes of your cluster, including your scheduler, jupyter server and worker nodes. These changes can be made easily by overriding the settings used by helm chart by writing your own config.yaml file. Here is my config.yaml file
# config.yaml
worker:
replicas: 8
env:
- name: EXTRA_CONDA_PACKAGES
value: numba xarray -c conda-forge
- name: EXTRA_PIP_PACKAGES
value: gcsfs s3fs dask-ml --upgrade
# We want to keep the same packages on the worker and jupyter environments
jupyter:
enabled: true
env:
- name: EXTRA_CONDA_PACKAGES
value: numba xarray matplotlib -c conda-forge
- name: EXTRA_PIP_PACKAGES
value: gcsfs s3fs dask-ml --upgrade
Now update your helm install with this command
$ helm upgrade billowing-labradoodle stable/dask -f config.yaml
Check your pods and make sure the status says they are all Running with the command “kubectl get pods”.
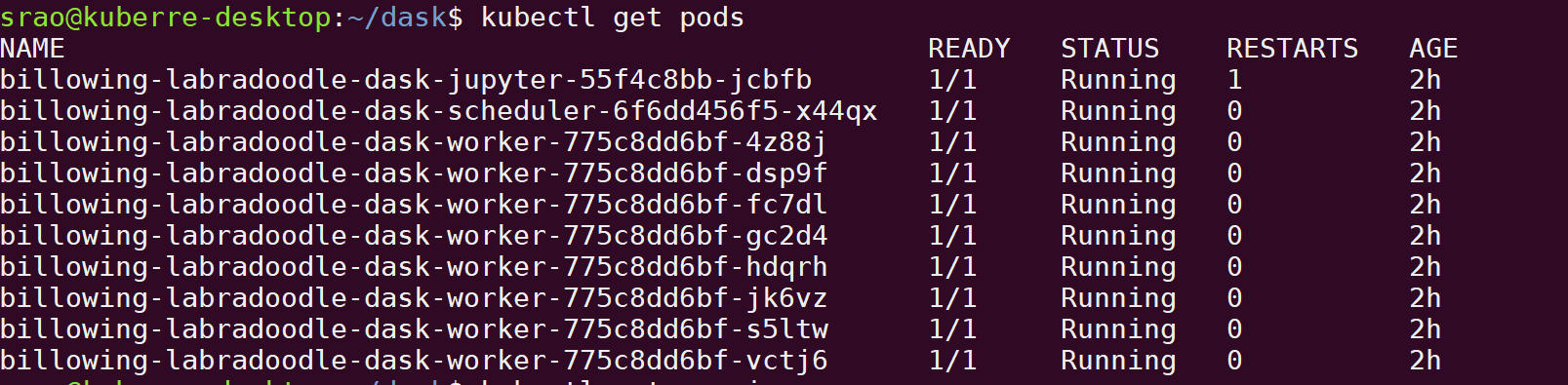
Now run the following command to get the external IP for your jupyter server and scheduler server. I have shortened the external-ip names so you can see what the result looks like.
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
billowing-labradoodle-dask-jupyter LoadBalancer 100.xx.xxx.93 a251--.amazonaws.com 80:32431/TCP 1h
billowing-labradoodle-dask-scheduler LoadBalancer 100.xx.xxx.136 a026--.amazonaws.com 8786:32624/TCP,80:31475/TCP 1h
kubernetes ClusterIP 100.xx.x.1 <none> 443/TCP 1h
Now copy paste the external IP into two browser windows. You should see the Jupyter hub login page and Scheduler page show up. If it doesn’t show up, just be patient and wait a few minutes. Typically the Scheduler page comes up pretty fast and Jupyter hub page takes a while. Eventually you will be greeted by the login page.
11. Finally Running the New York Taxi Example. Type in ‘dask’ as password for jupyterhub and login. Go into the examples folder and open the 05-nyc-taxi.ipynb notebook. If you were to run this now, it will run.. but it will be really slow and no where close to how fast the demo ran in the pycon video. It eventually occured to me that the given example is using csv files from google storage, whereas all our infrastructure we setup is on AWS. Of course there will be a huge delay! These files need to go over the network between two providers and to top it off, these files are huge.. about close to 2 gigs each. After I realized my mistake, I changed the code to use files from s3 instead and finally the notebook ran as fast as the demo!! Here is the code you need to change to use s3 instead of google cloud (also on MattMatthew Rocklin’s article). The thing to notice in the screenshot below is the number of Workers, the number of Cores and the total Memory across all the workers in step 3 -
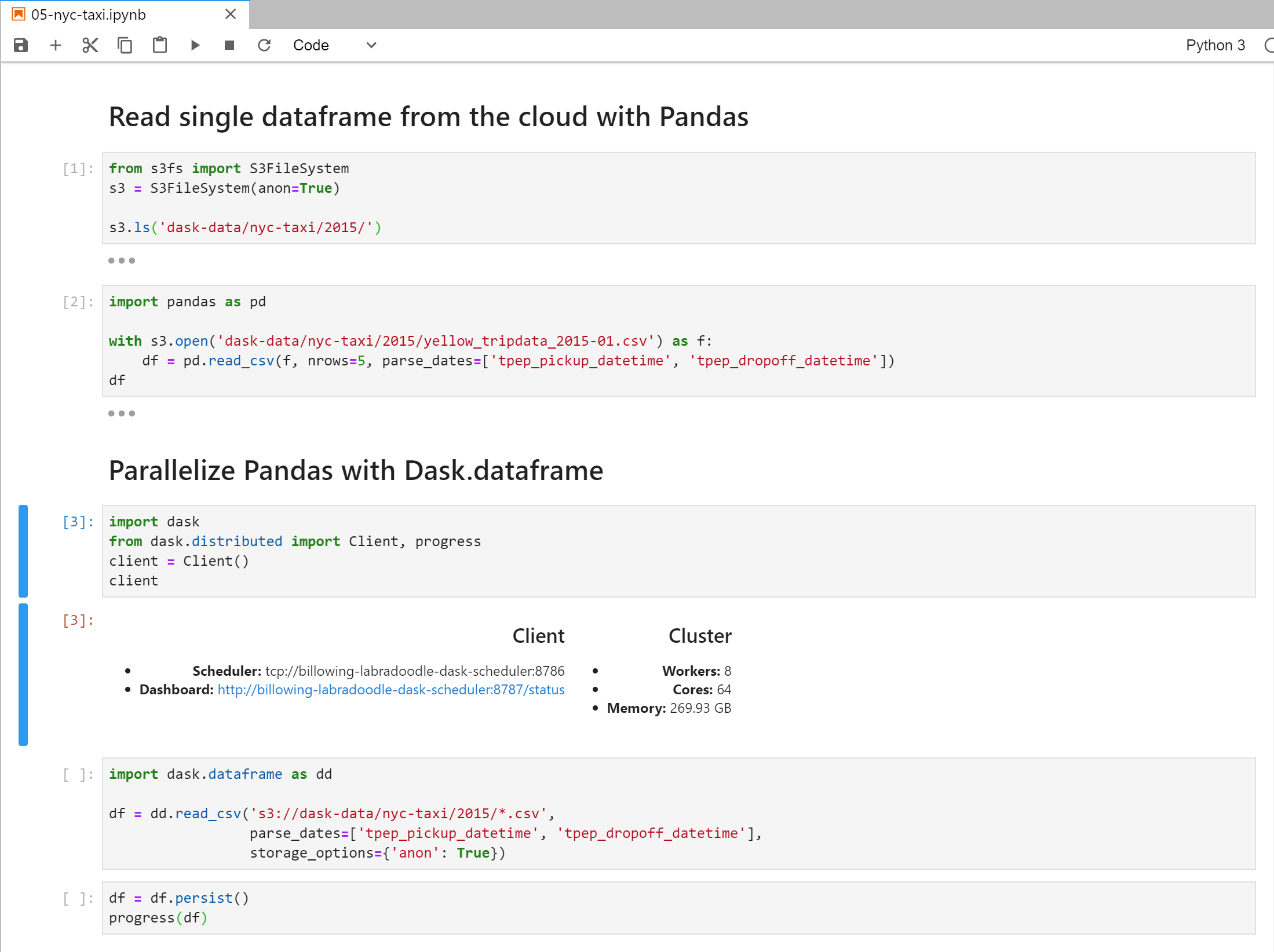
from s3fs import S3FileSystem
s3 = S3FileSystem(anon=True)
s3.ls('dask-data/nyc-taxi/2015/')
import pandas as pd
with s3.open('dask-data/nyc-taxi/2015/yellow_tripdata_2015-01.csv') as f:
df = pd.read_csv(f, nrows=5, parse_dates=['tpep_pickup_datetime', 'tpep_dropoff_datetime'])
df
import dask
from dask.distributed import Client, progress
client = Client()
client
import dask.dataframe as dd
df = dd.read_csv('s3://dask-data/nyc-taxi/2015/*.csv',
parse_dates=['tpep_pickup_datetime', 'tpep_dropoff_datetime'],
storage_options={'anon': True})
df = df.persist()
progress(df)
The rest is the same. Hope this helps somebody!